
Capitolo 11 Liste
Le liste sono uno degli oggetti più versatili e utili in R. Possiamo pensare alle liste come a dei grandi raccoglitori di altri oggetti. La caratteristica principale delle liste è proprio questa, ovvero la capacità di contenere tipologie diverse di oggetti al loro interno come ad esempio vettori, dataframe, matrici e anche altre liste.
A differenza di dataframe e matrici dove gli elementi sono tra loro in relazione, gli elementi di una lista sono completamente indipendenti. Una lista, infatti, può contenere oggetti completamente diversi tra loro sia per tipologia che per dimensioni, senza che vi sia alcuna relazione o vincolo.
Un modo utile per immaginarsi una lista (vedi Figura 11.1) è pensare ad un corridoio di un albergo dove ogni porta conduce ad una stanza diversa per caratteristiche, numero di elementi e così via. E’ importante notare come gli elementi siano disposti in un preciso ordine e quindi possano essere identificati tramite il loro indice di posizione, in modo analogo a quanto visto con gli elementi di un vettore.

Figure 11.1: Esempio concettuale di una lista
Da un punto di vista pratico la lista è un oggetto molto semplice, simile ad un vettore, e molte delle sue caratteristiche sono in comune con gli altri oggetti che abbiamo già affrontato. Tuttavia, la difficltà principale risiede nella sua indicizzazione poichè, data la loro grande versatilità, le strutture delle liste possono ragiungere notevoli livelli di complessità.
Vediamo ora come creare una lista e i diversi modi per sselezionare i suoi elementi. Come vedremo ci sono molte somiglianze nell’utilizzo dei dataframe e delle matrici. Quando necessario, si farà riferimento al capitolo precedente per far notare aspetti in comune e differenze tra queste due strutture di dati.
11.1 Creazione di Liste
Il comando per creare una lista è list():
Nonostante il parametro nome_oggetto_x non sia necessario, come vedremo è assolutamente consigliato rinominare tutti gli elementi della lista per agevolare l’indicizzazione. Se non nominiamo gli elementi, infatti, questi saranno identificati solo tramite il loro indice di posizione, ovvero un numero progressivo \(1...n\) esattamente come nel caso dei vettori. Questo rende meno intutiva la successiva selezione degli elementi.
Quindi, se nel nostro workspace abbiamo degli oggetti diversi come una semplice variabile, un vettore e un dataframe, possiamo raccoglieere tutti questi elementi dentro un’unica lista. Ad esempio:
# Una variabile
my_value <- "Prova"
# Un vettore
my_vector <- c(1, 3, 5, 6, 10)
# Un dataframe
my_data <- data.frame(id = 1:6,
gender = rep(c("m", "f"), times = 3),
y = 1:6)
# Creiamo la lista
my_list <- list(elemento_1 = my_value,
elemento_2 = my_vector,
elemento_3 = my_data)
my_list
## $elemento_1
## [1] "Prova"
##
## $elemento_2
## [1] 1 3 5 6 10
##
## $elemento_3
## id gender y
## 1 1 m 1
## 2 2 f 2
## 3 3 m 3
## 4 4 f 4
## 5 5 m 5
## 6 6 f 6Esercizi
Considerando gli oggetti creati nei precedenti capitoli, esegui i seguenti esercizi (soluzioni):
- Crea la lista
esperimento_1contenente:- DataFrame
data_wide - la matrice
A - il vettore
x - la variabile
info = "Prima raccolta dati"
- DataFrame
- Crea la lista
esperimento_2contenente:- DataFrame
data_long - la matrice
C - il vettore
y - la variabile
info = "Seconda raccolta dati"
- DataFrame
11.2 Selezione Elementi
Come dicevamo in precedenza, ogni elemento di una lista possiende il suo indice di posizione, ovvero un valore numerico progressivo in modo del tutto analogo a quanto visto per gli elementi di un vettore. Tuttavia, c’è un’importante differenza per quanto riguarda la modalità di selezione in base al tipo di oggetto che si vuole ottenere come risultato. Infatti, mentre con i vettori usavamo le singole parentesi quadre my_vector[i] per accedere direttamente all’elemento alla posizione \(i\), con le liste abbiamo due alternative:
my_list[i]- utilizzando le singole parentesi quadre ([i]) otteniamo come risultato un oggetto di tipo lista con all’interno l’elemento alla posizione \(i\). Questo non ci permette, tuttavia, di accedere direttamente ai suoi valori.my_list[[i]]- utilizzando le doppie parentesi quadre ([[i]]) estraiamo dalla lista l’elemento alla posizione \(i\) e come risultato otteniamo l’oggetto stesso. Questo ci permette quindi di accedere direttamente ai suoi valori.
Vediamo la differenza nel seguente esempio:
my_list
## $elemento_1
## [1] "Prova"
##
## $elemento_2
## [1] 1 3 5 6 10
##
## $elemento_3
## id gender y
## 1 1 m 1
## 2 2 f 2
## 3 3 m 3
## 4 4 f 4
## 5 5 m 5
## 6 6 f 6
# Indicizzazione [ ]
my_list[2]
## $elemento_2
## [1] 1 3 5 6 10
class(my_list[2]) # una lista
## [1] "list"
# Indicizzazione [[]]
my_list[[2]]
## [1] 1 3 5 6 10
class(my_list[[2]]) # un vettore
## [1] "numeric"Questa differenza nel risultato ottenuto usando le singole parentesi quadre ([ ]) o le doppie parentesi quadre ([[ ]]) è molto importante perché influirà sulle successive operazioni che potremmo compiere. Ricordiamo che nel primo caso ([ ]) ottenimo una lista con i soli elementi selezionati, mentre nel secondo caso ([[ ]]) accediamo direttamente all’oggetto selezionato.
Questa distinzione diventa chiara applicando una funzione generica allo stesso elemento indicizzato in modo diverso oppure usando la funzione str() per capire la struttura. Vediamo come solo accedendo direttamente all’elemento possiamo eseguire le normali operazioni, mentre, indicizzando con una sola parentesi, l’oggetto ottenuto è una lista con un singolo elemento.
# Applichiamo la media al vettore `elemento_2` indicizzato con 1 o 2 parentesi
mean(my_list[2])
## Warning in mean.default(my_list[2]): argument is not numeric or logical:
## returning NA
## [1] NA
mean(my_list[[2]])
## [1] 5
# Vediamo la struttura
str(my_list[2])
## List of 1
## $ elemento_2: num [1:5] 1 3 5 6 10
str(my_list[[2]])
## num [1:5] 1 3 5 6 10Il diverso tipo di selezione ottenuto con l’utilizzo delle singole o doppie parentesi quadre è definito nel seguente modo:
- singole parentesi quadre (
[ ]) - restituisce un oggetto della stessa classe (i.e., tipologia) dell’oggetto iniziale - doppie parentesi quadre (
[[ ]]) - estrae un elemento dall’oggetto iniziale restituendo un oggetto non necessariamente della stessa classe (i.e., tipologia)
Vediamo quindi come sia possibile utilizzare le doppie parentesi anche con i vettori e i dataframe ma in questo caso il risultato non differeisce dalla normale procedura di selezione.
# Vettori
my_vector[2]
## [1] 3
my_vector[[2]]
## [1] 3
# Dataframe
my_data[, 2]
## [1] "m" "f" "m" "f" "m" "f"
my_data[[2]] # la selezione è posibile solo sulle colonne
## [1] "m" "f" "m" "f" "m" "f"Nota infine come l’uso di singole parentesi quadre ([ ]) permette di selezionare più elementi contemporaneamente, mentre le doppie parentesi quadre ([[ ]]) permettono di estrarre solo un elemento alla volta
Selezione Operatore $
In alternativa all’uso delle doppie parentesi quadre ([[ ]]) è possibile, in modo analogo ai dataframe, accedere agli elementi di una lista utilizzando l’operatore $ ed indicando il loro nome:
my_list$nome_elemento- l’operatore$ci permette di accedere direttamente all’oggetto desiderato.
Vediamo alcuni esempi riprendendo la lista my_list create precedentemente.
# Selezionare "elemento_1"
my_list$elemento_1
## [1] "Prova"
# Selezionare "elemento_3"
my_list$elemento_3
## id gender y
## 1 1 m 1
## 2 2 f 2
## 3 3 m 3
## 4 4 f 4
## 5 5 m 5
## 6 6 f 6Nota come il nome degli elementi possa essere usato anche con le parentesi quadre.
## $elemento_1
## [1] "Prova"
##
## $elemento_2
## [1] 1 3 5 6 10Utilizzo Elementi e Successive Selezioni
Una volta che abbiamo estratto un elemento da una lista, è possibile utilizzare l’oggetto nel modo che preferiamo. Possiamo sia assegnare l’elemento ad nuovo oggetto da utilizzare successvamente, oppure eseguire le funzioni o altre operazioni generiche direttamente sul comando della selezione.
# Media dei valori dell' "elemento_2"
# Assegno l'oggetto
my_values <- my_list$elemento_2
mean(my_values)
## [1] 5
# Calcolo direttamente
mean(my_list$elemento_2)
## [1] 5Chiaramente le operazione che possiamo svolgere, come ad esempio ulteriori selezioni, dipendono dalla specifica tipologia e struttura dell’oggetto selezionato.
# ---- Seleziono il primo valore dell'oggetto "elemento_2" ----
my_list$elemento_2
## [1] 1 3 5 6 10
my_list$elemento_2[1]
## [1] 1
my_list[[2]][1] # equivalente a alla precedente
## [1] 1
#---- Seleziono la colonna "gender" dell'oggetto "elemento_3" ----
my_list$elemento_3$gender
## [1] "m" "f" "m" "f" "m" "f"
# Altre scritture equivalenti
my_list[[3]]$gender
## [1] "m" "f" "m" "f" "m" "f"
my_list[[3]][, 2]
## [1] "m" "f" "m" "f" "m" "f"
my_list[[3]][, "gender"]
## [1] "m" "f" "m" "f" "m" "f"11.2.1 Utilizzi Avanzati Selezione
Vediamo ora alcuni utilizzi avanzati della selezione di elementi di un dataframe.
Modificare gli Elementi
In modo analogo agli altri oggetti, possiamo modificare dei valori selezionando il vecchio elemento della lista e utilizzo la funzione <- (o =) per assegnare il nuovo elemento. Nota come in questo caso sia possibile uttilizzare sia le singole parentesi quadre ([ ]) che le doppie parentesi quadre ([[ ]]).
my_list
## $elemento_1
## [1] "Prova"
##
## $elemento_2
## [1] 1 3 5 6 10
##
## $elemento_3
## id gender y
## 1 1 m 1
## 2 2 f 2
## 3 3 m 3
## 4 4 f 4
## 5 5 m 5
## 6 6 f 6
# sostituiamo il primo elemento
my_list[1] <- "Un nuovo elemento"
# sostituiamo il secondo elemento
my_list[[2]] <- "Un altro nuovo elemento"
my_list
## $elemento_1
## [1] "Un nuovo elemento"
##
## $elemento_2
## [1] "Un altro nuovo elemento"
##
## $elemento_3
## id gender y
## 1 1 m 1
## 2 2 f 2
## 3 3 m 3
## 4 4 f 4
## 5 5 m 5
## 6 6 f 6Eliminare Elementi
In modo analogo agli altri oggetti, per eliminare degli elementi da una lista, è necessario indicare all’interno delle parentesi quadre gli indici di posizione degli elementi che si intende eliminare, preceduti dall’operatore - (meno). In questo caso è necessario l’utilizzo delle singole parentesi quadre ([ ]).
# Elimino il secondo elemento
my_list[-2]
## $elemento_1
## [1] "Un nuovo elemento"
##
## $elemento_3
## id gender y
## 1 1 m 1
## 2 2 f 2
## 3 3 m 3
## 4 4 f 4
## 5 5 m 5
## 6 6 f 6Ricorda come l’operazione di eliminazione sia comunque un’operazione di selezione. Pertanto è necessario salvare il risultato ottenuto se si desidera mantenere le modifiche.
Esercizi
Esegui i seguenti esercizi (soluzioni)
- Utilizzando gli indici numerici di posizione selziona i dati dei soggetti
subj_1esubj_4riguardanti le variabiliage,genderegruppodal DataFramedata_widecontenuto nella listaesperimento_1. - Compi la stessa selezione dell’esercizio precedente usando però questa volta il nome dell’oggetto per selezionare il DateFrame dalla lista.
- Considerando la lista
esperimento_2seleziona gli oggettidata_long,yeinfo - Cambia i nomi degli oggetti contenuti nella lista
esperimento_2rispettivamente in"dati_esperimento","matrice_VCV","codici_Id"e"note"
11.3 Funzioni ed Operazioni
Vediamo ora alcune funzioni frequentemente usate e le comuni operazioni eseguite con le liste (vedi Tabella 11.1).
| Funzione | Descrizione |
|---|---|
| length(nome_df) | Numero di elementi nella lista |
| names(nome_df) | Nomi degli elementi della lista |
| nome_list$nome_obj <- oggetto | Aggiungi un nuovo elemento alla lista |
| c(nome_df) | Unire più liste |
| unlist(nome_df) | Ottieni un vettori di tutti gli elementi |
| str(nome_df) | Struttura del dataframe |
| summary(nome_df) | Summary del dataframe |
Descriviamo ora nel dettaglio alcuni particolari utilizzi, considrando come esempio la lista my_list qui definita. Nota che i nomi degli elemnti sono stati omessi volutamente.
11.3.1 Attributi di una Lista
Anche le liste come gli altri oggetti, hanno degli attributi ovvero delle utili informazioni riguardanti l’oggetto stesso. Vediamo ora come valutare la dimensione di una lista e i nomi dei suoi elementi.
Dimensione
Per valutare la dimensione di una lista, ovvero il numero di elementi che contiene, possiamo utilizzare la funzione length()
Nomi Elementi
Per accedere ai nomi degli elementi di una lista, è possibile utilizzare la funzione names(). Se i nomi non sono stati specificati al momento della creazione, otterremo il valore NULL.
Per impostare i nomi degli elementi, sarà quindi necessario assegnare a names(my_list) un vettore di caratteri con i nomi di ciascun elemento.
11.3.2 Unire Liste
Per aggiungere elementi ad una lista è possibile sia creare un nuovo elemento con l’operatore $, in modo annalogo ai datafame, sia combinare più liste con la funzione c().
my_list$name <- new_obj
Con la scrittura my_list$name <- new_obj aggiungiamo alla lista in oggetto un nuovo elemento di cui dobbiamo specificare il nome e gli assegnamo l’oggetto new_obj.
c()
Con la funzione c() possiamo combinare più liste insieme. Nota come sia necessario che i nuovi oggetti che vogliamo includere siano effettivamente una lista, altrimenti potremmo non ottenere il risultato desiderato:
# ERRORE: combino una lista con un vettore
new_vector <- 1:3
c(my_list, new_vector)
## $Variabile
## [1] "Prova"
##
## $Vettore
## [1] 1 3 5 6 10
##
## $Dataframe
## id gender y
## 1 1 m 1
## 2 2 f 2
## 3 3 m 3
## 4 4 f 4
## 5 5 m 5
## 6 6 f 6
##
## $new_obj
## [1] "Un nuovo elemento"
##
## [[5]]
## [1] 1
##
## [[6]]
## [1] 2
##
## [[7]]
## [1] 3
# CORRETTO: combino una lista con un'altra lista
c(my_list, list(new_vector = 1:3))
## $Variabile
## [1] "Prova"
##
## $Vettore
## [1] 1 3 5 6 10
##
## $Dataframe
## id gender y
## 1 1 m 1
## 2 2 f 2
## 3 3 m 3
## 4 4 f 4
## 5 5 m 5
## 6 6 f 6
##
## $new_obj
## [1] "Un nuovo elemento"
##
## $new_vector
## [1] 1 2 3In questo caso sarà necessario salvare il risultato ottenuto per mantenere i cambiamenti.
11.3.3 Informazioni Lista
Vediamo infine alcune funzioni molto comuni usate per ottenere informazioni riassuntive riguardo gli elementi di una lista:
str()ci permete di valutare la struttura della lista ottenendo utili informazini quali in numero di elementi e la loro tipologia
str(my_list)
## List of 4
## $ Variabile: chr "Prova"
## $ Vettore : num [1:5] 1 3 5 6 10
## $ Dataframe:'data.frame': 6 obs. of 3 variables:
## ..$ id : int [1:6] 1 2 3 4 5 6
## ..$ gender: chr [1:6] "m" "f" "m" "f" ...
## ..$ y : int [1:6] 1 2 3 4 5 6
## $ new_obj : chr "Un nuovo elemento"summary()ci permete avere delle informazioni riassuntive degli elementi tuttavia risulta poco utlie
11.4 Struttura Nested
Al contrario dei vettori che si estendono in lunghezza o dei dataframe/matrici che sono caratterizzati da righe e colonne, la peculiarità della lista (oltre alla lunghezza come abbaimo visto) è il concetto di profondità. Infatti una lista può contenere al suo interno una o più liste di fatto creando una struttura nidificata molto complessa. Nonostante la struttura più complessa, il principio di indicizzazione e creazione è lo stesso. La Figura 11.2 rappresenta l’idea di una lista nidificata (o nested):
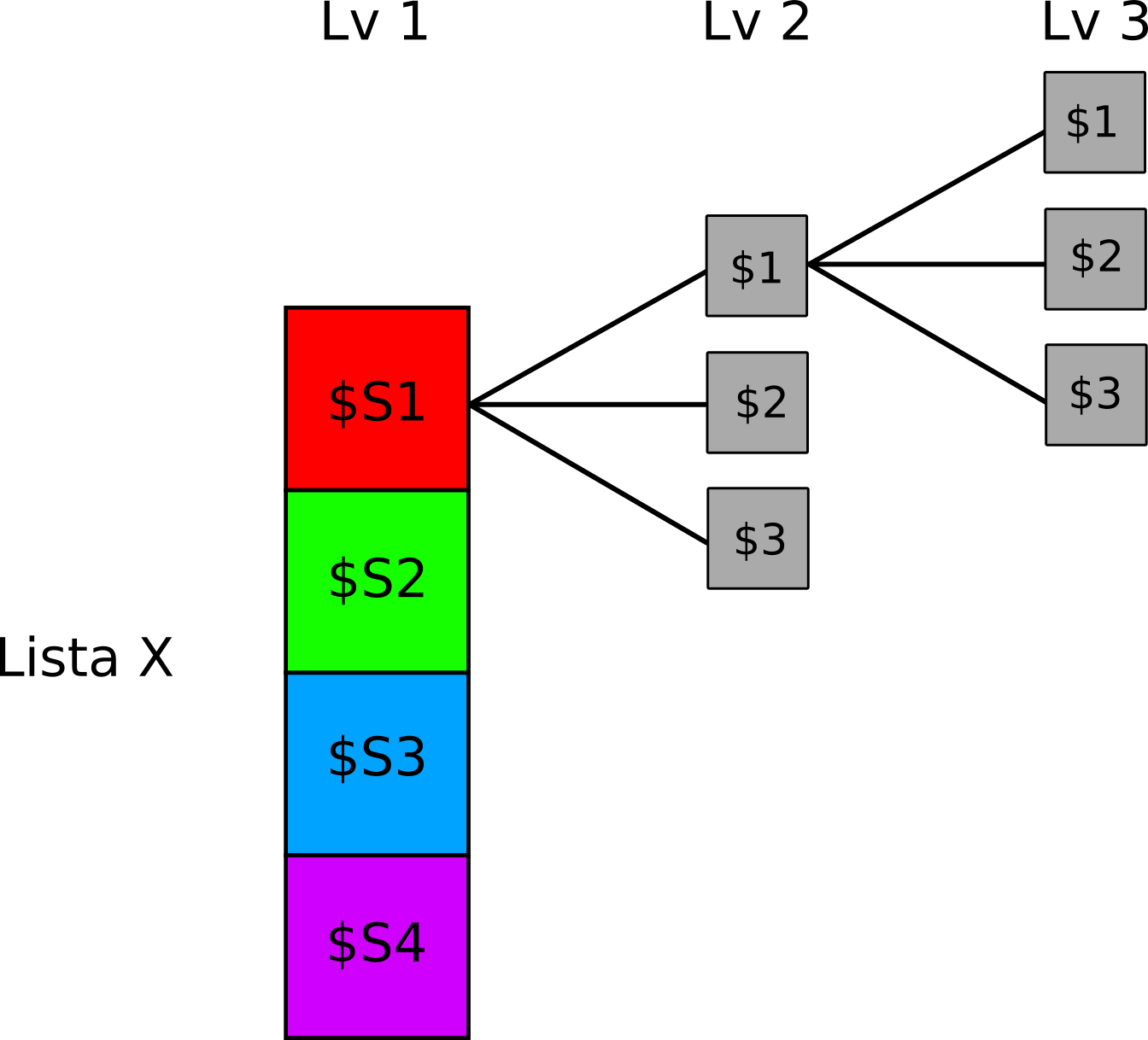
Figure 11.2: Rappresentazione concettuale di una lista nested
Per fare un esempio pratico, immaginiamo che \(n\) soggetti abbiamo eseguito \(k\) diversi esperimenti e vogliamo organizzare questa struttura di dati in R in modo efficace e ordinato. Possiamo immaginare una lista esperimenti che contiene:
- Ogni soggetto come una lista, chiamata
s1, s2, ..., sn - Ogni elemento della lista-soggetto è un dataframe per lo specifico esperimento chiamato
exp1, exp2, ..., expn
# Per comodità ripetiamo lo stesso esperimento e lo stesso soggetto
# Esperimento generico
exp_x <- data.frame(
id = 1:10,
gender = rep(c("m", "f"), each = 5),
y = 1:10
)
# Soggetto generico
sx <- list(
exp1 = exp_x,
exp2 = exp_x,
exp3 = exp_x
)
# Lista Completa
esperimenti <- list(
s1 = sx,
s2 = sx,
s3 = sx
)
str(esperimenti)
## List of 3
## $ s1:List of 3
## ..$ exp1:'data.frame': 10 obs. of 3 variables:
## .. ..$ id : int [1:10] 1 2 3 4 5 6 7 8 9 10
## .. ..$ gender: chr [1:10] "m" "m" "m" "m" ...
## .. ..$ y : int [1:10] 1 2 3 4 5 6 7 8 9 10
## ..$ exp2:'data.frame': 10 obs. of 3 variables:
## .. ..$ id : int [1:10] 1 2 3 4 5 6 7 8 9 10
## .. ..$ gender: chr [1:10] "m" "m" "m" "m" ...
## .. ..$ y : int [1:10] 1 2 3 4 5 6 7 8 9 10
## ..$ exp3:'data.frame': 10 obs. of 3 variables:
## .. ..$ id : int [1:10] 1 2 3 4 5 6 7 8 9 10
## .. ..$ gender: chr [1:10] "m" "m" "m" "m" ...
## .. ..$ y : int [1:10] 1 2 3 4 5 6 7 8 9 10
## $ s2:List of 3
## ..$ exp1:'data.frame': 10 obs. of 3 variables:
## .. ..$ id : int [1:10] 1 2 3 4 5 6 7 8 9 10
## .. ..$ gender: chr [1:10] "m" "m" "m" "m" ...
## .. ..$ y : int [1:10] 1 2 3 4 5 6 7 8 9 10
## ..$ exp2:'data.frame': 10 obs. of 3 variables:
## .. ..$ id : int [1:10] 1 2 3 4 5 6 7 8 9 10
## .. ..$ gender: chr [1:10] "m" "m" "m" "m" ...
## .. ..$ y : int [1:10] 1 2 3 4 5 6 7 8 9 10
## ..$ exp3:'data.frame': 10 obs. of 3 variables:
## .. ..$ id : int [1:10] 1 2 3 4 5 6 7 8 9 10
## .. ..$ gender: chr [1:10] "m" "m" "m" "m" ...
## .. ..$ y : int [1:10] 1 2 3 4 5 6 7 8 9 10
## $ s3:List of 3
## ..$ exp1:'data.frame': 10 obs. of 3 variables:
## .. ..$ id : int [1:10] 1 2 3 4 5 6 7 8 9 10
## .. ..$ gender: chr [1:10] "m" "m" "m" "m" ...
## .. ..$ y : int [1:10] 1 2 3 4 5 6 7 8 9 10
## ..$ exp2:'data.frame': 10 obs. of 3 variables:
## .. ..$ id : int [1:10] 1 2 3 4 5 6 7 8 9 10
## .. ..$ gender: chr [1:10] "m" "m" "m" "m" ...
## .. ..$ y : int [1:10] 1 2 3 4 5 6 7 8 9 10
## ..$ exp3:'data.frame': 10 obs. of 3 variables:
## .. ..$ id : int [1:10] 1 2 3 4 5 6 7 8 9 10
## .. ..$ gender: chr [1:10] "m" "m" "m" "m" ...
## .. ..$ y : int [1:10] 1 2 3 4 5 6 7 8 9 10Ora la struttura è molto più complessa, ma se abbiamo chiara la Figura 11.2 e l’indicizzazione per le liste precedenti, accedere agli elementi della lista esperimenti è semplice ed intuitivo. Se vogliamo accedere al dataset del soggetto 3 che riguarda l'esperimento 2:
# Con indici numerici
esperimenti[[3]][[2]] # elemento 3 (una lista) e poi l'elemento 2
## id gender y
## 1 1 m 1
## 2 2 m 2
## 3 3 m 3
## 4 4 m 4
## 5 5 m 5
## 6 6 f 6
## 7 7 f 7
## 8 8 f 8
## 9 9 f 9
## 10 10 f 10
# Con i nomi (molto più intuitivo)
esperimenti$s3$exp2
## id gender y
## 1 1 m 1
## 2 2 m 2
## 3 3 m 3
## 4 4 m 4
## 5 5 m 5
## 6 6 f 6
## 7 7 f 7
## 8 8 f 8
## 9 9 f 9
## 10 10 f 10Se il vantaggio di un dataframe rispetto ad una matrice è palese, quale è la vera utilità delle liste essendo “semplicemente” dei contenitori? I vantaggi principali che rendono le liste degli oggetti estremamente potenti sono:
- Organizzare strutture complesse di dati: come abbiamo visto nell’esempio precedente, insiemi di oggetti nidificati possono essere organizzati in un oggetto unico senza avere decine di singoli oggetti nel workspace.
- Effettuare operazioni complesse su più oggetti parallelamente. Immaginate di avere una lista di dataframe strutturalmente simili ma con dati diversi all’interno. Se volete applicare una funzione ad ogni dataframe potete organizzare i dati in una lista e usare le funzioni dell’
applyfamily che vedremo nei prossimi capitoli. TODO
Infine, proprio per la loro flessibilità, le liste sono spesso utilizzate da vari pachetti per restituire i risultati delle analisi statistiche svolte. Saper accedere ai vari elementi di una lista risulta quindi necessario per ottenere specifiche infomazioni e risultati.