
Capitolo 7 Vettori
I vettori sono la struttura dati più semplice tra quelle presenti in R. Un vettore non è altro che un insieme di elementi disposti in uno specifico ordine e possiamo quindi immaginarlo in modo simile a quanto rappresentato in Figura 7.1.
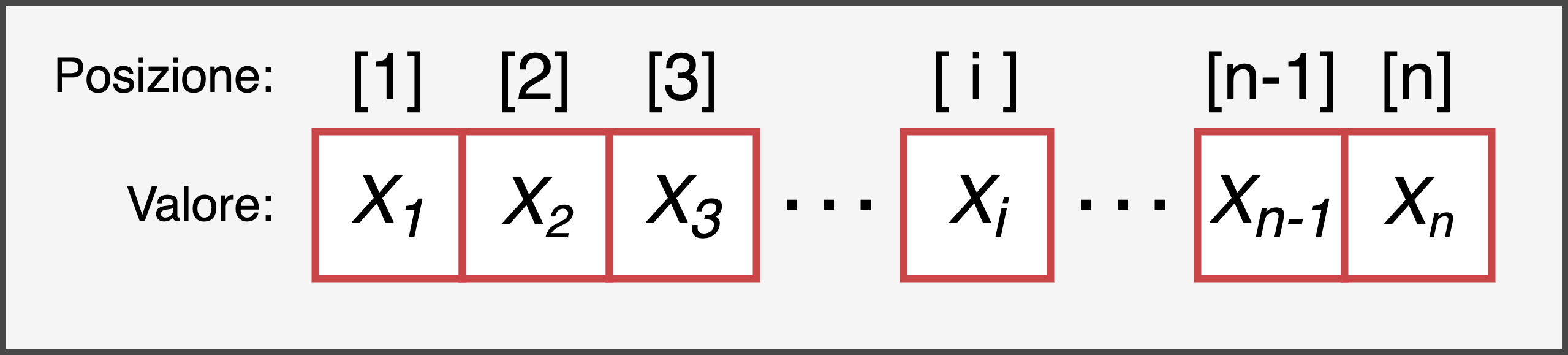
Figure 7.1: Rappresentazione della struttura di un vettore di lunghezza n
Due caratteristiche importanti di un vettore sono:
- la lunghezza - il numero di elementi da cui è formato il vettore
- la tipologia - la tipologia di dati da cui è formato il vettore. Un vettore infatti deve esssere formato da elementi tutti dello stesso tipo e pertanto esistono diversi vettori a seconda della tipologia di dati da cui è formato (valori numerici, valori interi, valori logici, valori carattere).
E’ fondamentale inoltre sottolineare come ogni elemento di un vettore sia caratterizzato da:
- un valore - ovvero il valore dell’elemento che può essere di qualsiasi tipo ad esempio un numero o una serie di caratteri.
- un indice di posizione - ovvero un numero intero positivo che identifica la sua posizione all’interno del vettore.
Notiamo quindi come i vettori \(x\) e \(y\) così definiti: \[ x = [1, 3, 5];\ \ \ y = [3, 1, 5], \] sebbene includano gli stessi elementi, non sono identici poichè differiscono per la loro disposizione. Tutto questo ci serve solo per ribadire come l’ordine degli elementi sia fondamentale per la valutazione di un vettore.
Vedimao ora come creare dei vettori in R e come compiere le comuni operazini di selezione e manipolazione di vettori. Successivamente approfondiremo le caratteristiche dei vettori valutandone le diverse tipologie.
7.1 Creazione
In realtà abbiamo già incontrato dei vettori nei precedenti capitoli poichè anche le variabili con un singolo valore altro non sono che un vettore di lunghezza 1. Tuttavia, per creare dei vettori di più elementi dobbiamo utilizzare il comando c(), ovvero “combine”, indicando tra le parentesi i valori degli elementi nella sucessione desiderata e separati da una virgola. Avremo quindi la seguente sintassi:
Nota come gli elementi di un vettore debbano essere tutti della stessa tipologia ad esempio valori numerici o valori carattere.
In altrentativa è possibile utilizzare qualsiasi funzione che restituisca come output una sequenza di valori sotto forma di vettore. Tra le funzioni più usate per creare delle sequenze abbiammo:
<from>:<to>- Genera una sequenza di valori numerici crescenti (o decrescenti) dal primo valore indicato (<from>) al secondo valore indicato (<to>) a step di 1 (o -1 ).
# sequenza crescente
1:5
## [1] 1 2 3 4 5
# sequenza decrescente
2:-2
## [1] 2 1 0 -1 -2
# sequenza con valori decimali
5.3:10
## [1] 5.3 6.3 7.3 8.3 9.3seq(from = , to = , by = , length.out = )- Genera una sequenza regolare di valori numerici compresi trafrometocon incrementi indicati daby, oppure di lunghezza conplessiva indicata dalength.out(vedi?seq()per maggiori dettagli).
# sequenza a incrementi di 2
seq(from = 0, to = 10, by = 2)
## [1] 0 2 4 6 8 10
# sequenza di 5 elementi
seq(from = 0, to = 1, length.out = 5)
## [1] 0.00 0.25 0.50 0.75 1.00rep(x, times = , each = )- Genera una sequenza di valori ripetendo i valori contenuti inx. I valori dixposssono essere ripetuti nello stesso ordine più volte specificandotimesoppure ripetuti ciascuno più volte specificandoeach(vedi?rep()per maggiori dettagli).
Esercizi
Famigliarizza con la creazione di vettori (soluzioni):
- Crea il vettore
xcontenente i numeri 4, 6, 12, 34, 8 - Crea il vettore
ycontenente tutti i numeri pari compresi tra 1 e 25 (?seq()) - Crea il vettore
zcontenente tutti i primi 10 multipli di 7 partendo da 13 (?seq()) - Crea il vettore
sin cui le lettere"A","B"e"C"vengono ripetute nel medesimo ordine 4 volte (?rep()) - Crea il vettore
tin cui le letter"A","B"e"C"vengono ripetute ognuna 4 volte (?rep()) - Genera il seguente output in modo pigro, ovvero scrivendo meno codice possibile ;)
## [1] "foo" "foo" "bar" "bar" "foo" "foo" "bar" "bar"7.2 Selezione Elementi
Una volta creato un vettore potrebbe essere necessario selezionare uno o più dei suoi elementi. In R per selezionare gli elementi di un vettore si utilizzano le parentesi quadre [] dopo il nome del vettore, indicando al loro interno l’indice di posizione degli elementi desiderati:
Attenzione, non devo quindi indicare il valore dell’elemento desiderato ma il suo indice di posizione. Ad esempio:
# dato il vettore
my_numbers <- c(2,4,6,8)
# per selezionare il valore 4 utilizzo il suo indice di posizione ovvero 2
my_numbers[2]
## [1] 4
# Se utilizzassi il suo valore (ovvero 4)
# otterrei l'elemento che occupa la 4° posizione
my_numbers[4]
## [1] 8Per selezionare più elementi è necessario indicare tra le parentesi quadre tutti gli indici di posizione degli elementi desiderati. Nota come non sia possibile fornire semplicemente i singoli indici numerici ma questi devono essere raccolti in un vettore, ad esempio usando la funzione c(). Praticamente usiamo un vetore di indici per selezionare gli elemeni desiderati dal nostro vettore iniziale.
# ERRATA selezione più valori
my_numbers[1,2,3]
## Error in my_numbers[1, 2, 3]: incorrect number of dimensions
# CORRETTA selezione più valori
my_numbers[c(1,2,3)]
## [1] 2 4 6
my_numbers[1:3]
## [1] 2 4 6Nota come l’operazione di selezione non modifichi l’oggetto iniziale. Pertanto è necessario salvare il risultato della selezione se si desidera mantenere le modifiche.
Cosa accade se utiliziamo un indice di posizione maggiore del numero di elementi del nostro vettore?
R non restituisce un errore ma il valore NA ovvero Not Available, per indicare che nessun valore è disponibile.
Osserviamo infine anche altri comportamenti particolari o possibili errori nella selezione di elementi.
- L’indice di posizione deve essere un valore numerico e non un carattere.
# ERRATA selezione più valori
my_numbers["3"]
## [1] NA
# CORRETTA selezione più valori
my_numbers[3]
## [1] 6- I numeri decimali vengono ignorati e non “arrotondati”
- Utilizzando il valore 0 ottengo un vettore vuoto
7.2.1 Utilizzi Avanzati Selezione
Vediamo ora alcuni utilizzi avanzati della selezione di elementi di un vettore. In particolare impareremo a:
- utilizzare gli operatori relazionali e logici per selezionare gli elementi di un vettore
- modificare l’ordine degli elementi
- creare nuove combinazioni
- sostituire degli elementi
- eliminare degli elementi
Operatori Relazionali e Logici
Un’utile funzione è quella di selezionare tra gli elementi di un vetore quelli che rispetano una certa condizione. Per fare questo dobbiamo specificare all’interno delle parentesi quadre la proposizione di interesse utilizzando gli operatori relazionali e logici (vedi Capitolo 3.2).
Possiamo ad esempio selezionare da un vettore numerico tutti gli elementi maggiori di un certo valore, oppure selezionare da un vettore di caratteri tutti gli elementi uguali ad una data stringa.
# Vettore numerico - seleziono elemeni maggiori di 0
my_numbers <- -5:5
my_numbers[my_numbers >= 0]
## [1] 0 1 2 3 4 5
# Vettore caratteri - seleziono elemeni uguali a "bar"
my_words <- rep(c("foo", "bar"), times = 4)
my_words[my_words == "bar"]
## [1] "bar" "bar" "bar" "bar"Per capire meglio questa operazione è importante notare come nello stesso comando ci siano in realtà due passaggi distinti:
- Vettore logico (vedi Capitolo 7.4.4) - quando un vettore è valutato in una proposizione, R restituisce un nuovo vettore che contiene per ogni elemento del vettore iniziale la risposta (
TRUEoFALSE) alla nostra proposizione. - Selezione - utilizziamo il vettore logico ottenuto per selezionare gli elementi dal vettore iniziale. Gli elementi associati al valore
TRUEsono selezionati mentre quelli associati al valoreFALSEsono scartati.
Rendiamo espliciti questi due passaggi nel seguente codice:
Ordinare gli Elementi
Gli indici di posizione possono essere utilizzati per ordinare gli elementi di un vettore a seconda delle necessità.
messy_vector <- c(5,1,7,3)
# Altero l'ordine degli elementi
messy_vector[c(4,2,3,1)]
## [1] 3 1 7 5
# Ordino gli elementi per valori crescenti
messy_vector[c(2,4,1,3)]
## [1] 1 3 5 7Per ordinare gli elementi di un vettore in ordine crescente o decrescente (sia alfabetico che numerico), è possibile utilizzare la funzione sort() specificando l’argomento decreasing. Vedi l’help page della funzione per ulteriori informazioni (?sort()).
# Ordine alfabetico
my_letters <- c("cb", "bc", "ab", "ba", "cb", "ab")
sort(my_letters)
## [1] "ab" "ab" "ba" "bc" "cb" "cb"
# ordine decrescente
sort(messy_vector, decreasing = TRUE)
## [1] 7 5 3 1Nota come esista anche la funzione order() ma questa sia un false-friend perchè non ci fornisce direttamente un vettore con gli elementi ordinati ma bensì gli indici di posizione per riordinare gli elementi (?order()). Vediamo nel seguente esempio come utilizzare questa funzione:
Combinazioni di Elementi
Gli stessi indici di posizione possono essere richiamati più volte per ripetere gli elementi nelle combinazioni desiderate formando un nuovo vettore.
Modificare gli Elementi
Un importante utilizzo degli indici riguarda la modifica di un elemento di un vettore. Per sostituire un vecchio valore con un nuovo valore, posso utilizzare la funzione assign (<- o =) come nell’esempio:
my_names <- c("Andrea", "Bianca", "Carlo")
# Modifico il nome "Bianca" in "Beatrice"
my_names[2] <- "Beatrice"
my_names
## [1] "Andrea" "Beatrice" "Carlo"Per sostituire il valore viene indicato alla sinistra dell’operatore assign il valore che si vuole modificare e alla destra il nuovo valore. Nota come questa operazione possa essere usata per aggiungere anche nuovi elementi al vettore.
Eliminare gli Elementi
Per eliminare degli elementi da un vettore, si indicano all’interno delle parentesi quadre gli indici di posizione degli elementi da eliminare preceduti dall’operatore - (meno). Nel caso di più elementi è anche possibile indicare il meno solo prima del comando c(), ad esempio il comando x[c(-2,-4)] diviene x[-c(2,4)].
my_words <- c("foo", "bar", "baz", "qux")
# Elimino "bar"
my_words[-2]
## [1] "foo" "baz" "qux"
# Elimino "foo" e "baz"
my_words[-c(1,3)] # oppure my_words[c(-1, -3)]
## [1] "bar" "qux"Nota come l’operazione di eliminazione sia comunque un’operazione di selezione. Pertanto è necessario salvare il risultato ottenuto se si desidera mantenere le modifiche.
7.2.1.1 which()
La funzione which() è molto utile per ottenere la posizione all’interno di un vettore associata ad una certa condizione logica. In altri termini se vogliamo sapere in quale posizione sono i valori > 5 in un certo vettore numerico possiamo usare la funzione which(x > 5) dove x è chiaramente il nostro vettore numerico.
## [1] TRUE TRUE TRUE FALSE TRUE FALSE FALSE FALSE FALSE FALSE
## [1] 1 2 3 5Come vedete, la funzione which() essenzialmente restituisce la posizione (e non il valore) dove la condizione testata è TRUE. E’ importante notare che queste due scritture sono equivalenti:
## [1] 9.748922 7.090858 5.665718 12.286197
## [1] 9.748922 7.090858 5.665718 12.286197Infatti, come abbiamo visto possiamo indicizzare un vettore sia con un’altro vettore che ci indica la posizione degli elementi da estrarre che un vettore logico di lunghezza uguale al vettore originale.
Esercizi
Esegui i seguenti esercizi (soluzioni):
- Del vettore
xseleziona il 2°, 3° e 5° elemento - Del vettore
xseleziona i valori 34 e 4 - Dato il vettore
my_vector = c(2,4,6,8)commenta il risultato del comandomy_vector[my_vector] - Del vettore
yseleziona tutti i valori minori di 13 o maggiori di 19 - Del vettore
zseleziona tutti i valori compresi tra 24 e 50 - Del vettore
sseleziona tutti gli elementi uguali ad"A" - Del vettore
tseleziona tutti gli elementi diversi da"B" - Crea un nuovo vettore
uidentico asma dove le"A"sono sostituite con la lettera"U" - Elimina dal vettore
zi valori 28 e 42
7.3 Funzioni ed Operazioni
Vediamo ora alcune utili funzioni e comuni operazioni che è possibile svolgere con i vettori (vedi Tabella 7.1).
| Funzione | Descrizione |
|---|---|
| nuovo_vettore <- c(vettore1, vettore2) | Unire più vettori in un unico vettore |
| length(nome_vettore) | Valutare il numero di elementi contenuti in un vettore |
| vettore1 + vettore2 | Somma di due vettori |
| vettore1 - vettore2 | Differenza tra due vettori |
| vettore1 * vettore2 | Prodotto tra due vettori |
| vettore1 / vettore2 | Rapporto tra due vettori |
Nota che l’esecuzione di operazioni matematiche (e.g., +, -, *, / etc.) è possibile sia rispetto ad un singolo valore sia rispetto ad un altro vettore:
- Singolo valore - l’operazione sarà svolta per ogni elemento del vettore rispetto al singolo valore fornito.
- Altro vettore - l’operazione sarà svolta per ogni coppia di elementi dei due vettori. E’ quindi necessario che i due vettori abbiano la stessa lunghezza, ovvero lo stesso numero di elementi.
x <- 1:5
y <- 1:5
# Sommo un valore singolo
x + 10
## [1] 11 12 13 14 15
# Somma di vettori (elemento per elemento)
x + y
## [1] 2 4 6 8 10Qualora i vettori differiscano per la loro lunghezza, R ci presenterà un warning avvisandoci del problema ma eseguirà comunque l’operazione utilizzando più volte il vettore più corto.
x + c(1, 2)
## Warning in x + c(1, 2): longer object length is not a multiple of shorter object
## length
## [1] 2 4 4 6 6Tuttavia, compiere operazioni tra vettori di diversa lunghezza (anche se multipli) dovrebbe essere evitato poichè è facile causa di errori ed incomprensioni.
In R la maggior parte degli operatori sono vettorizzati, ovvero calcolano direttamente il risultato per ogni elemento di un vettore. Questo è un grandissimo vantaggio poichè ci permette di essere molto efficienti e coincisi nel codice.
Senza vettorizzazione, ogni operazione tra due vettori richiederebbe di specificare l’operazione per ogni elemento del vettore. Nel precedente esempio della somma tra x e y avremmo dovuto usare il seguente codice:
Nota come questo sia valido anche per gli operatori relazionali e logici. Infatti valutando una proposizione rispetto ad un vettore, otterremmo una risposta per ogni elemento del vettore
Esercizi
Esegui i seguenti esercizi (soluzioni):
- Crea il vettore
junendo i vettorixedz. - Elimina gli ultimi tre elementi del vettore
je controlla che i vettorijeyabbiano la stessa lunghezza. - Calcola la somma tra i vettori
jey. - Moltiplica il vettore z per una costante
k=3. - Calcola il prodotto tra i primi 10 elementi del vettore
yed il vettorez.
7.4 Data Type
Abbiamo visto come sia necessario che in un vettore tutti gli elementi siano della stessa tipologia. Avremo quindi diversi tipi di vettori a seconda della tiopologia di dati che contengono.
In R abbiamo 4 principali tipologie di dati, ovvero tipologie di valori che possono essere utilizzati:
character- Stringhe di caratteri i cui valori alfannumerici vengono delimitati dalle doppie vigolette"Hello world!"o virgolette singole'Hello world!'.double- Valori reali con o senza cifre decimali ad esempio27o93.46.integer- Valori interi definiti apponendo la letteraLal numero desiderato, ad esempio58L.logical- Valori logiciTRUEeFALSEusati nelle operazioni logiche.
Possiamo verificare la tipologia di un valore utlizzando la funzione typeof().
typeof("foo")
## [1] "character"
typeof(2021)
## [1] "double"
typeof(2021L) # nota la lettera L
## [1] "integer"
typeof(TRUE)
## [1] "logical"Esistono molte altre tipologie di dati tra cui complex (per rappresentare i numeri complessi del tipo \(x + yi\)) e Raw (usati per rappresenttare i valori come bytes) che però riguardano usi poco comuni o comunque molto avanzati di R e pertanto non verranno trattati.
Questa distinzione tra le varie tipologie di dati deriva dalla modalità con cui il computer rappresenta internamente i diversi valori. Sappiamo infatti che il computer non possiede caratteri ma solamente bits, ovvero successioni di 0 e 1 ad esempio 01000011.
Senza scendere nel dettaglio, per ottimizzare l’uso della memoria i diversi valori vengono “mappati” utilizzando i bits in modo differente a seconda delle tipologie di dati. Pertanto in R il valore 24 sarà rappresentato diversamente a seconda che sia definitio come una stringa di caratteri ("24"), un numero intero (24L) o un numero double (24).
Integer vs Double
In particolare un aspetto poco intuitivo riguarda la differenza tra valori double e integer. Mentre i valori interi possono essere rappresentati con precisione dal computer, non tutti i valori reali posssono essere rappresentati esattamente utilizzando il numero massimo di 64 bit. In questi casi i loro valori vengonno quindi approsimati e, sebbene questo venga fatto con molta precisione, a volte potrebbe portare a dei risultati inaspettati. Nota infatti come nell’esempio seguente non otteniamo zero, ma osserviamo un piccolo errore dovuto all’approsimazione dei valori double.
E’ importante tenere a mente questo problema nei test di ugualianza dove l’utilizzo dell’operatore == potrebbe generare delle risposte inaspettate. In genere viene quindi preferita la funzione all.equal() che prevede un certo margine di tolleranza (vedi ?all.equal() per ulteriori dettagli).
my_value == 2 # Problema di approsimazione
## [1] FALSE
all.equal(my_value, 2) # Test con tolleranza
## [1] TRUERicorda infine che i computer hanno un limite rispetto al massimo valore e minimo valore che possono rappresentare sia per quanto riguarda i valori interi che i valori reali. Per approfondire vedi https://stat.ethz.ch/pipermail/r-help/2012-January/300250.html.
Vediamo ora i diversi tipi di vettori a seconda della tipologia di dati utilizzati.
7.4.1 Character
I vettori formati da stringhe di caratteri sono definiti vettori di caratteri. Per valutare la tipologia di un oggetto possiamo utilizzare la funzione class(), mentre ricordiamo che la funzionne typeof() valuta la tipologia di dati. In questo caso otteniamo per entrambi il valore character.
my_words<-c("Foo","Bar","foo","bar")
class(my_words) # tipologia oggetto
## [1] "character"
typeof(my_words) # tipologia dati
## [1] "character"Non è possibile eseguire operazioni aritmetiche con vettori di caratteri ma solo valutare relazioni di uguaglianza o disuguaglianza ripetto ad un’altra stringa.
7.4.2 Numeric
In R, se non altrimenti specificato, ogni valore numerico viene rappresentato come un double indipendentemente che abbia o meno valori decimali. I vettori formati da valori double sono definiti vettori numerici. In R la tipologia del vettore è indicata con numeric mentre i dati sono double.
my_values <- c(1,2,3,4,5)
class(my_values) # tipologia oggetto
## [1] "numeric"
typeof(my_values) # tipologia dati
## [1] "double"I vettori numerici sono utilizzati per compiere qualsiasi tipo di operazioni matematiche o logico-relazionali.
7.4.3 Integer
In R per specificare che un valore è un numero intero viene aggiunta la lettera L immediatamente dopo il numero. I vettori formati da valori interi sono definiti vettori di valori interi. In R la tipologia del vettore è indicata con integer allo stesso modo dei dati.
my_integers <- c(1L,2L,3L,4L,5L)
class(my_integers) # tipologia oggetto
## [1] "integer"
typeof(my_integers) # tipologia dati
## [1] "integer"Come per i vettori numerici, i vettori di valori interi possono esssere utilizzati per compiere qualsiasi tipo di operazioni matematiche o logico-relazionali. Nota tuttavia che operazioni tra integer e doubles restituiranno dei doubles ed anche nel caso di operazioni tra integers il risultato potrebbe non essere un integer.
7.4.4 Logical
I vettori formati da valori logici (TRUE e FALSE) sono definiti vettori logici. In R la tipologia del vettore è indicata con logical allo stesso modo dei dati.
my_logical <- c(TRUE, FALSE, TRUE)
class(my_logical) # tipologia oggetto
## [1] "logical"
typeof(my_logical) # tipologia dati
## [1] "logical"I vettori di valori logici possono esssere utilizzati con gli operatori logici.
my_logical & c(FALSE, TRUE, TRUE)
## [1] FALSE FALSE TRUE
my_logical & c(0, 1, 3)
## [1] FALSE FALSE TRUETuttavia ricordiamo che ai valori TRUE e FALSE sono associati rispettivamente i valori numerici 1 e 0 (o più precisamente i valori interi 1L e 0L). Pertanto è possibile eseguire anche operazioni matematiche dove verrano automaticamente considerati i rispettivi valori numerici. Ovviamente il risultato ottenuto sarà un valore numerico e non logico.
Utilizzando le funzioni sum() e mean() con un vettore logico, possiamo valutare rispettivamente il numero totale e la percentuale di elementi che hanno soddisfatto una certa condizione logica.
Esistono due famiglie di funzioni che permettono rispettivamene di testare e di modificare la tipologia dei dati.
is.* Family
Per testare se un certo valore (o un vettore di valori) appartiene ad una specifica tipologia di dati, possimao utilizzare una tra le seguenti funzioni:
is.vector()- valuta se un oggetto è un generico vettore di qualsiasi tipo
is.character()- valuta se l’oggetto è una stringa
is.character("2021") # TRUE
is.character(2021) # FALSE
is.character(2021L) # FALSE
is.character(TRUE) # FALSEis.numeric()- valuta se l’oggetto è un valore numerico indipendentemente che sia un double o un integer
is.numeric("2021") # FALSE
is.numeric(2021) # TRUE
is.numeric(2021L) # TRUE
is.numeric(TRUE) # FALSEis.double()- valuta se l’oggetto è un valoredouble
is.integer()- valuta se l’oggetto è un valore intero
is.integer("2021") # FALSE
is.integer(2021) # FALSE
is.integer(2021L) # TRUE
is.integer(TRUE) # FALSEis.logical()- valuta se l’oggetto è un valore logico
is.logical("2021") # FALSE
is.logical(2021) # FALSE
is.logical(2021L) # FALSE
is.logical(TRUE) # TRUEas.* Family
Per modificare la tipologia di un certo valore (o un vettore di valori), possimao utilizzare una tra le seguenti funzioni:
as.character()- trasforma l’oggetto in una stringa
as.numeric()- trasforma l’oggetto in undouble
as.numeric("foo") # Non valido con stringhe di caratteri
## Warning: NAs introduced by coercion
## [1] NA
as.numeric("2021") # Valido per stinghe di cifre
## [1] 2021
as.numeric(2021L)
## [1] 2021
as.numeric(TRUE)
## [1] 1as.double()- trasforma l’oggetto in undouble
as.double("2021") # Valido per stinghe di cifre
## [1] 2021
as.double(2021L)
## [1] 2021
as.double(TRUE)
## [1] 1as.integer()- trasforma l’oggetto in uninteger
as.integer("2021") # Valido per stinghe di cifre
## [1] 2021
as.integer(2021.6) # Tronca la parte decimale
## [1] 2021
as.integer(TRUE)
## [1] 1as.logical()- trasforma un oggetto numerico in un valore logico qualsiasi valore diverso da 0 viene consideratoTRUE
7.4.5 Valori speciali
Vediamo infine alcuni valori speciali utilizzatti in R con dei particolari significati e che richiedono specifici accorgimenti quando vengono manipolati:
NULL- rappresenta l’oggetto nullo, ovvero l’assenza di un oggetto. Spesso viene restituito dalle funzioni quano il loro output è indefinito.NA- rappresenta un dato mancate (Not Available). E’ un valore costante di lunghezza 1 che può essere utlizzato per qualsiasi tipologia di dati.NaN- indica un risulato matematico che non può essere rappresentato come un valore numerico (Not A Number). E’ un valore costante di lunghezza 1 che può essere utlizzato come valore numerico (non intero).
Inf(o-Inf) - indica un risultato matematico inifinito (o infinito negativo). E’ anche utilizzato per rappresentare numeri estremamente grandi.
E’ importante essere consapevoli delle caratteristiche di questi valori poichè presentano dei comportamenti peculiari che, se non corretamente gestiti, possono generare conseguenti errori nei codici. Descriviamo ora alcune delle carateristiche più importanti.
Lunghezza Elementi
Notiamo innanzitutto come mentre NULL sia effettivamente un oggetto nullo, ovvero privo di dimensione, NA sia uno speciale valore che rappresenta la presenza di un dato mancate. Pertanto NA, a differenza di NULL, è effettivamente un valore di lunghezza 1.
# Il valore NULL è un oggetto nullo
values_NULL <- c(1:5, NULL)
length(values_NULL)
## [1] 5
values_NULL # NULL non è presente
## [1] 1 2 3 4 5
# Il valore NA è un oggetto che testimonia un'assenza
values_NA <- c(1:5, NA)
length(values_NA)
## [1] 6
values_NA # NA è presente
## [1] 1 2 3 4 5 NAAllo stesso modo, anche i valori NaN e Inf sono effettivamente dei valori di lunghezza 1 usati per testimoniare speciali risultati numerici.
Propagazione Valori
Altra importante caratteristica è quella che viene definita propagazione dei valori ovvero le operazioni che includono questi speciali valori resituiscono a loro volta lo stesso speciale. Ciò significa che questi valori si propagheranno di risultato in risultato all’interno del nostro codice se non opportunamente gestiti.
NULL- osserviamo come se il valoreNULLviene utilizzato in una qualsiasi operazione matematica il risultato sarà un vettore numerico vuoto di dimensione 0, il quale può essere interpretato in modo simile (seppur non identico) al valoreNULL
NA- quandoNAviene utilizzato in una qualsiasi operazione matematica il risultato sarà nuovamene unNA.
NaN- quandoNaNviene utilizzato in una qualsiasi operazione matematica il risultato sarà nuovamene unNaN.
Inf(o-Inf) - qualoraInf(o-Inf) siano utilizzati in un’operazione matematica il risultato seguirà le comuni regole delle operazioni tra infiti.
Testare Valori
E’ importante ricordare come per testare l apresenza di uno di questi valori speciali siano presenti delle funzioni specifiche della famiglia is.*. Non deve mai essere utlizzato il comune operatore di uguaglianza == poichè non fornisce i risultai corretti.
is.null
is.na
is.nan
Inf
Operatori Logici
Un particolare comportamento riguarda i risultati ottenute con gli operatori logici dove la propagazione del valore non segue sempre le attese. Osserviamo i diversi casi:
NULL- ottenimo come da attese un vettore logico vuoto di dimensione 0
TRUE & NULL # logical(0)
TRUE | NULL # logical(0)
FALSE & NULL # logical(0)
FALSE | NULL # logical(0)NA- non otteniamo come da attese sempre il valoreNAma in alcune condizioni la proposizione saraTRUEoFALSE
NaN- otteniamo gli stessi risultati del caso precedente utilizzando il valoreNA
Inf- essendo un valore numerico diverso da zero otteniamo i rissultati secondo le attese
Un comportamento tanto strano per quanto riguarda l’utilizzo del valore NA con gli operatori logici può essere spiegato dal fatto che il valore NA in realtà sia un valore logico che indica la mancanza di una risposta.
Pertanto le proposizioni vengono correttamente seguendo le comuni regole. Nel caso di TRUE | NA la proposizione è giudicata TRUE perchè con l’operatore di disgiunzione è sufficiente che una delle due parti sia vera avvinchè la proposizione sia vera. Nel caso di FALSE & NA, invece, la proposizione è giudicata FALSE perchè con l’operatore di congiunzione è sufficiente che una delle due parti sia falsa avvinchè la proposizione sia falsa. LA non risposta indicata da NA i questi casi è ininfluente, mentre determina il risultato nei restanti casi quando la seconda parte della proposizione deve essere necessariamente valutata. A questo punto gli operatori restituiscono NA poichè incapaci di determinare la risposta.
Per quanto riguarda il caso del valore NaN è sufficinete ricordare che tale valore sia comunque un valore numerico di cui però non è possibile identificare il valore.
Tutti i valori numerici sono considerati validi nelle operazioni logiche, dove qualsiais numero diveros da zero è valutato TRUE. Pertanto viene seguito lo stesso ragionamento precedente, quando non è necessario valutare entrambe le parti della proposizione viene fornita una risposta, mentre si ottiene NA negli altri casi quando R è obbligato a valutare entrambe la parti ma è incapace di fornire una risspossta poichè non può determinare il valore di NaN.
Lavorare in presenza di dati mancanti accadrà nella maggior parte dei casi. Molte delle funzioni presenti in R hanno già delle opzioni per rimuovere automaticamete eventuali dati mancanti così da poter ottenre correttamete i risultati.
Tuttavia, è importante non avvalersi in modo automatico di tali opzioni ma avere cura di valutare attentamente la presenza di dati mancanti. Questo ci permetterà di indagare possibili pattern riguardanti i dati mancanti e valutare la loro possibile influenza sui nostri risultati e la validità elle conclusioni.
Inoltre sarà fondamentale controllare sempre l’effittiva dimensione del campione utilizzato nelle vari analisi. Ad esempio se non valutato attentamente potremmo non ottenere il numero effettivo di valori su cui è stata calcolata precedentemente la media.