
Capitolo 14 Programmazione Iterativa
L’essenza della maggior parte delle operazioni nei vari linguaggi di programmazione è quella del concetto di iterazione. Iterazione significa ripetere una porzione di codice un certo numero di volte o fino anche una condizione viene soddisfatta.
Molte delle funzioni che abbiamo usato finora come la funzione sum() o la funzione mean() si basano su operazioni iterative. In R, purtroppo o per fortuna, userete abbastanza raramente delle iterazioni tramite loop anche se nella maggior parte delle funzioni sono presenti. Infatti molte delle funzioni implementate in R sono disponibili solo con pacchetti esterni oppure devono essere scritte manualmente implementando strutture iterative.
14.1 Loop
14.1.1 For
Il primo tipo di struttura iterativa viene denominata ciclo for. L’idea è quella di ripetere una serie di istruzioni un numero predefinito di volte.La Figura 14.1 rappresenta l’ idea di un ciclo for. In modo simile alle strutture condizionali del capitolo precedente, quando scriviamo un ciclo, entriamo in una parte di codice temporaneamente, eseguiamo le operazioni richieste e poi continuiamo con il resto del codice. Quello che nell’immagine è chiamato i è un modo convenzionale di indicare il conteggio delle operazioni. Se vogliamo ripetere un’operazione 1000 volte, i parte da 1 e arriva fino a 1000.

Figure 14.1: Rappresentazione for loop
Struttura For Loop
In R la scrittura del ciclo for è la seguente:
iè un nome generico per indicare la variabile conteggio che abbiamo introdotto prima. Può essere qualsiasi carattere, ma solitamente per un ciclo generico si utilizzano singole lettere comeiojproabilmente per una similarità con la notazione matematica che spesso utilizza queste lettere per indicare una serie di elementiinè l’operatore per indicare cheivaria rispetto ai valori specificati di seguitoc(...)è il range di valori che assumeràiin per ogni iterazione
Possiamo riformulare il codice in:
Ripeti le operazioni incluse tra {} un numero di volte uguale alla lunghezza di
c(...)e in questo ciclo,iassumerà, uno alla volta i valori contenuti inc(...).
Informalmente ci sono due tipi di ciclo, quello che utilizza un counter generico da assegnare a i e un’altro che utilizza direttamente dei valori di interesse.
Esempio
- Loop con direttamente i valori di interesse
# numerico
# caratteri
for (name in c("Alessio", "Beatrice", "Carlo")){
print(paste0("Ciao ", name))
}
## [1] "Ciao Alessio"
## [1] "Ciao Beatrice"
## [1] "Ciao Carlo"Loop che utilizza un counter generico per indicizzare gli elementi:
my_vector <- c(93, 27, 46, 99)
# i in 1:length(my_vector)
for (i in seq_along(my_vector)){
print(my_vector[i])
}
## [1] 93
## [1] 27
## [1] 46
## [1] 99Questa distinzione è molto utile e spesso fonte di errori. Se si utilizza direttamente il vettore e il nostro counter assume i valori del vettore, “perdiamo” un indice di posizione. Nell’esempio del ciclo con i nomi infatti, se volessimo sapere e stampare quale posizione occupa Alessio dobbiamo modificare l’approccio, puntando ad utilizzando anche counter generico. Possiamo crearlo fuori dal ciclo e aggiornarlo manualmente:
i <- 1
for (name in c("Alessio", "Beatrice", "Carlo")){
print(paste0(name, " è il numero ", i))
i <- i + 1
}
## [1] "Alessio è il numero 1"
## [1] "Beatrice è il numero 2"
## [1] "Carlo è il numero 3"In generale, il modo migliore è sempre quello di utilizzare un ciclo utilizza indici e non i valori effettivi, in modo da poter accedere comunque entrambe le informazioni.
Esempio: la funzione somma
Come introdotto all’inizio di questo capitolo, molte delle funzioni disponibili in R derivano da strutture iterative. Se pensiamo alla funzione sum() sappiamo che possiamo calcolare la somma di un vettore semplicemente con sum(x). Per capire appieno i cicli, è interessante pensare e implementare le funzioni comuni.
Se dovessimo sommare n numeri a mano la struttura sarebbe questa:
- prendo il primo numero \(x_1\) e lo sommo con il secondo \(x_2\)
- ottengo un nuovo numero
x_{1+2} - prendo il terzo numero \(x_3\) e lo sommo a
x_{1+2} - ottengo \(x_{1+2+3}\)
- ripeto questa operazione fino all’ultimo elemento di \(x_n\)
Come vedete, questa è una struttura iterativa, che conta da 1 alla lunghezza di \(x\) ed ogni iterazione somma il successivo con la somma dei precedenti. In R:
my_values <- c(2,4,6,8)
# Calcolare somma valori
my_sum <- 0 # inizializzo valore
for (i in seq_along(my_values)){
my_sum <- my_sum + my_values[i]
}
my_sum
## [1] 20La struttura è la stessa del nostro ragionamento in precedenza. Creo una variabile “partenza” che assume valore 0 ed ogni iterazione sommo indicizzando il rispettivo elemento.
Esempio: creo un vettore
Essendo che utilizziamo un indice che assume un range di valori, possiamo non solo accedere ad un vettore utilizzando il nostro indice ma anche creare o sostituire un vettore progressivamente.
# Calcola la somma di colonna
my_matrix <- matrix(1:24, nrow = 4, ncol = 6)
# Metodo non efficiente (aggiungo valori)
sum_cols <- c()
for( i in seq_len(ncol(my_matrix))){
sum_col <- sum(my_matrix[, i]) # calcolo i esima colonna
sum_cols <- c(sum_cols, sum_col) # aggiungo il risultato
}
sum_cols
## [1] 10 26 42 58 74 90
# Metodo efficiente (aggiorno valori)
sum_cols <- vector(mode = "double", length = ncol(my_matrix))
for( i in seq_along(sum_cols)){
sum_col <- sum(my_matrix[, i]) # calcolo i esima colonna
sum_cols[i] <- sum_col # aggiorno il risultato
}
sum_cols
## [1] 10 26 42 58 74 9014.1.2 While
Il ciclo while può essere considerato come una generalizzazione del ciclo for. In altri termini il ciclo for è un tipo particolare di ciclo while.
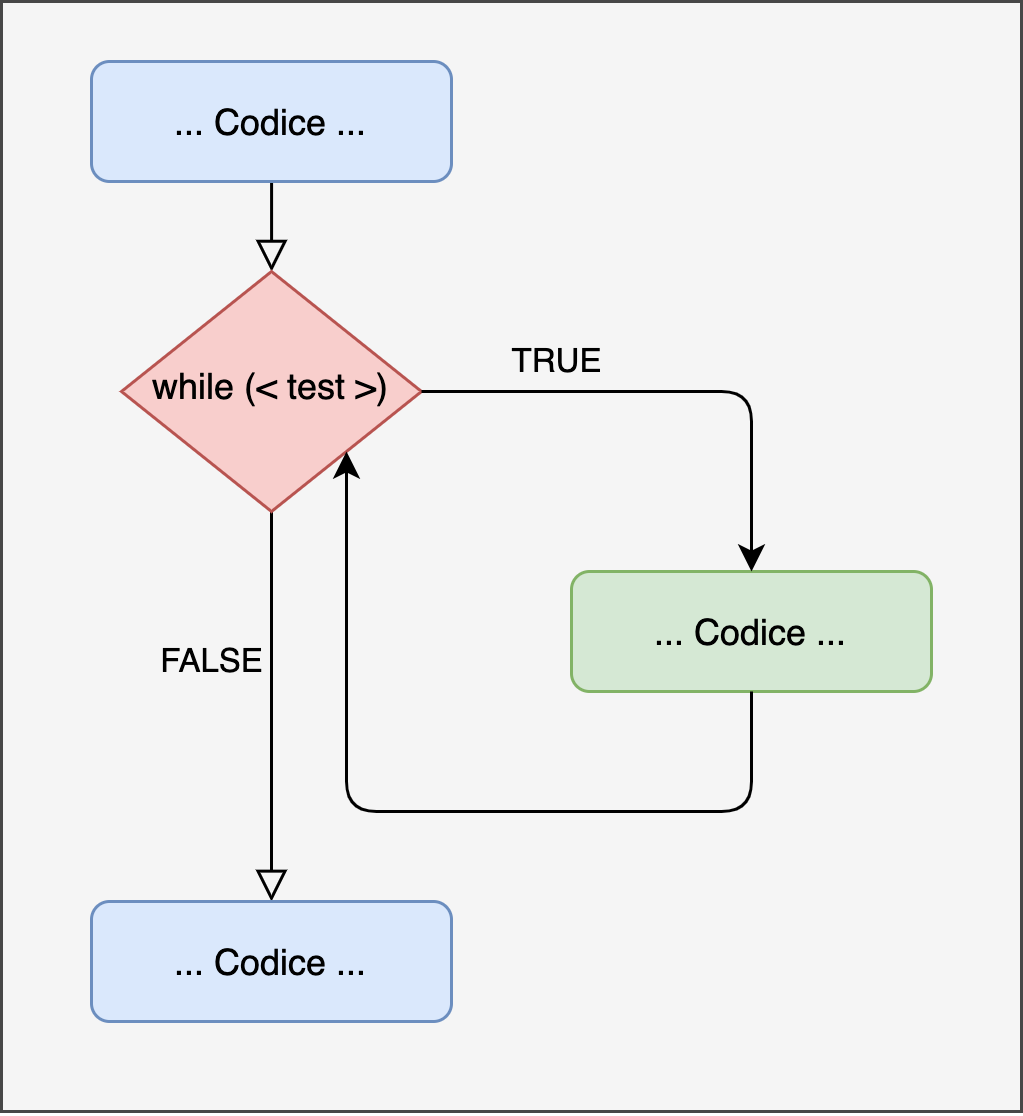
Figure 14.2: Rappresentazione while loop
Struttura While Loop
La scrittura è più concisa del ciclo for perchè non definiamo nessun counter o placeholder e nemmeno un vettore di valori. L’unica cosa che muove un ciclo while è una condizione logica (quindi con valori booleani TRUE e FALSE). Anche qui, parafrasando:
Ripeti le operazioni incluse tra {} fino a che la condizione
<test>è VERA.
In altri termini, ad ogni iterazione la condizione <test> viene valutata. Se questa è vera, viene eseguita l’operazione altrimenti il ciclo si ferma.
Esempio
Se vogliamo fare un conto alla rovescia
count <- 5
while(count >= 0){
print(count)
count <- count - 1 # aggiorno variabile
}
## [1] 5
## [1] 4
## [1] 3
## [1] 2
## [1] 1
## [1] 0Quando si scrive un ciclo while è importante assicurarsi di due cose:
- Che la condizione sia
TRUEinizialmente, altrimenti il ciclo non comincierà nemmeno - Che ad un certo punto la condizione diventi
FALSE(perchè abbiamo ottenuto il risultato o perchè è passato troppo tempo o iterazioni)
Se la seconda condizione non è rispettata, otteniamo quelli che si chiamano endless loop come ad esempio:
14.1.2.1 While e For
Abbiamo introdotto in precedenza che il for è un tipo particolare di while. Concettualmente infatti possiamo pensare ad un for come un while dove il nostro counter i incrementa fino alla lunghezza del vettore su cui iterare. In altri termini possiamo scrivere un for anche in questo modo:
14.1.3 Next e Brake
All’interno di una struttura iterativa, possiamo eseguire qualsiasi tipo di operazione, ed anche includere strutture condizionali. Alcune volte può essere utile saltare una particolare iterazione oppure interrompere il ciclo iterativo. In R tali operazioni posso essere eseguite rispettivamene coni comandi next e break.
next- passa all’iterazione successivabreak- interrompe l’esecuzione del ciclo
14.2 Nested loop
Una volta compresa la struttura iterativa, è facile espanderne le potenzialità inserendo un ciclo all’interno di un altro. Possiamo avere quanti cicli nested necessari, chiaramente aumenta non solo la complessità ma anche il tempo di esecuzione. Per capire al meglio cosa succede all’interno di un ciclo nested è utile visualizzare gli indici:
for(i in 1:3){ # livello 1
for(j in 1:3){ # livello 2
for(l in 1:3){ # livello 3
print(paste(i, j, l))
}
}
}
## [1] "1 1 1"
## [1] "1 1 2"
## [1] "1 1 3"
## [1] "1 2 1"
## [1] "1 2 2"
## [1] "1 2 3"
## [1] "1 3 1"
## [1] "1 3 2"
## [1] "1 3 3"
## [1] "2 1 1"
## [1] "2 1 2"
## [1] "2 1 3"
## [1] "2 2 1"
## [1] "2 2 2"
## [1] "2 2 3"
## [1] "2 3 1"
## [1] "2 3 2"
## [1] "2 3 3"
## [1] "3 1 1"
## [1] "3 1 2"
## [1] "3 1 3"
## [1] "3 2 1"
## [1] "3 2 2"
## [1] "3 2 3"
## [1] "3 3 1"
## [1] "3 3 2"
## [1] "3 3 3"Guardando gli indici, è chiaro che il ciclo più interno viene ultimato per primo fino ad arrivare a quello più esterno. La logica è la seguente:
- La prima iterazione entriamo nel ciclo più esterno
i = 1, poi in quello internoj = 1e in quello più internol = 1. - nella seconda iterazione siamo bloccati nel ciclo interno e quindi sia
ichejsaranno 1 mentrelsarà uguale a 2. - quando il ciclo
lsarà finito,isarà sempre 1 mentrejpasserà a 2 e così via
Un aspetto importante è l’utilizzo di indici diversi, infatti i valori i, j e l assumono valori diversi ad ogni iterazione e se usassimo lo stesso indice, non otterremo il risultato voluto.
Esercizi
- Scrivi una funzione che calcoli la media di un vettore numerico usando un for loop.
- Scrivi una funzione che dato un vettore numerico restituisca il valore massimo e minimo usando un for loop (attenti al valore di inizializzazione).
- Scrivi una funzione che per ogni iterazione generi \(n\) osservazioni da una normale (funzione
rnorm()) con media \(mu\) e deviazione standard \(sigma\), salva la media di ogni campione. I parametri della funzione saranno \(n\), \(mu\), \(sigma\) e \(iter\) (numero di iterazioni).
14.3 Apply Family
Ci sono una famiglia di funzioni in R estremamente potenti e versatili chiamate *apply. L’asterisco suggerisce una serie di varianti presenti in R che nonostante la struttura e funzione comune hanno degli obiettivi diversi:
apply: dato un dataframe (o matrice) esegue la stessa funzione su ogni riga o colonnatapply: dato un vettore di valori esegue la stessa funzione su ogni gruppo che è satato definitolapply: esegue la stessa funzione per ogni elemento di una lista. Restituisce ancora una listasapply: esegue la stessa funzione per ogni elemento di una lista. Restituisce se possibile un oggetto seplificato (un vettore, una matrice o un array)vapply: analogo asapplyma richiede di definire il tipo di dati restituitimapply: è la versione multivariata. Permette di applicare una funzione a più liste di elementi
Prima di illustrare le varie funzioni è utile capire la struttura generale. In generale queste funzioni accettano un oggetto lista quindi un insieme di elementi e una funzione. L’idea infatti è quella di avere una funzione che accetta altre funzioni come argomenti e applichi la funzione-argomento ad ogni elemento in input.
Queste funzioni, sopratutto in R, sono spesso preferite rispetto ad utilizzare cicli for per velocità, compattezza e versatilità.
Hadley Wickam[^talk-map] riporta un bellissimo esempio per capire la diffenza tra loop e *apply. Immaginiamo di avere una serie di vettori e voler applicare alcune funzioni ad ogni vettore, possiamo impostare un semplice loop in questo modo:
list_vec <- list(
vec1 <- rnorm(100),
vec2 <- rnorm(100),
vec3 <- rnorm(100),
vec4 <- rnorm(100),
vec5 <- rnorm(100)
)
means <- vector(mode = "numeric", length = length(list_vec))
medians <- vector(mode = "numeric", length = length(list_vec))
st_devs <- vector(mode = "numeric", length = length(list_vec))
for(i in seq_along(list_vec)){
means[i] <- mean(list_vec[[i]])
medians[i] <- median(list_vec[[i]])
st_devs[i] <- sd(list_vec[[i]])
}Nonostante sia perfettamente corretto, questa scrittura ha diversi problemi:
- E’ molto ridondante. Tra calcolare media, mediana e deviazione standard l’unica cosa che cambia è la funzione applicata mentre dobbiamo per ognuno preallocare una variabile, impostare l’indicizzazione in base all’iterazione per selezionare l’elemento della lista e memorizzare il risultato. Per migliorare questa scrittura possiamo mettere in una funzione tutta questa struttura (preallocazione, indicizzazione e memorizzazione) e utilizzare questa funzione con argomenti la lista di input e la funzione da applicare. Utilizzando la funzione
sapply:
means <- lapply(list_vec, mean)
means
## [[1]]
## [1] -0.1744844
##
## [[2]]
## [1] -0.001581971
##
## [[3]]
## [1] 0.003746107
##
## [[4]]
## [1] -0.1040844
##
## [[5]]
## [1] 0.2978849
medians <- lapply(list_vec, median)
medians
## [[1]]
## [1] -0.1336871
##
## [[2]]
## [1] 0.08244486
##
## [[3]]
## [1] 0.002455108
##
## [[4]]
## [1] -0.00886783
##
## [[5]]
## [1] 0.2095848
st_devs <- lapply(list_vec, sd)
st_devs
## [[1]]
## [1] 1.028626
##
## [[2]]
## [1] 1.056527
##
## [[3]]
## [1] 1.027976
##
## [[4]]
## [1] 0.9351077
##
## [[5]]
## [1] 1.04055Come vedete il codice diventa estremamente compatto, pulito e facile da leggere.
14.3.1 Quali funzioni applicare?
Prima di descrivere nel dettaglio ogni funzione *apply è importante capire quali tipi di funzioni possiamo usare all’interno di questa famiglia. In generale, qualsiasi funzione può essere applicata ma per comodità possiamo distinguerle in:
- funzioni già presenti in R
- funzioni personalizzate (create e salvate nell’ambiente principale)
- funzioni anonime
Nell’esempio precedente, abbiamo utilizzato la funzione mean semplicemente scrivendo lapply(lista, mean). Questo è possibile perchè mean necessita di un solo argomento. Se tuttavia volessimo applicare funzioni più complesse o aggiungere argomenti possiamo usare la scrittura più generale:
means <- lapply(list_vec, function(x) mean(x))
means
## [[1]]
## [1] -0.1744844
##
## [[2]]
## [1] -0.001581971
##
## [[3]]
## [1] 0.003746107
##
## [[4]]
## [1] -0.1040844
##
## [[5]]
## [1] 0.2978849L’unica differenza è che abbiamo definito una funzione anonima con la scrittura function(x) .... Questa scrittura si interpreta come “ogni elemento di list_vec diventa x, quindi applica la funzione mean() per ogni elemento di list_vec”. La funzione anonima permette di scrivere delle funzioni non salvate o presenti in R e applicare direttamente ad una serie di elementi. Possiamo anche usare funzioni più complesse come centrare ogni elemento di list_vec:
centered_list <- lapply(list_vec, function(x) x - mean(x))
centered_list
## [[1]]
## [1] 0.052024420 0.726941033 0.523133907 0.534116649 1.072538094
## [6] -1.748085116 0.436228769 1.090050776 0.188256343 1.904447568
## [11] -0.907720449 -0.098340775 0.356479804 1.683026192 1.778954510
## [16] -1.666991209 1.797794611 0.305873422 1.655606875 1.687802692
## [21] -0.767958869 -0.011200606 -0.926640234 1.382599658 -1.450454139
## [26] 0.279862739 -1.280958942 -0.179531732 0.080784364 1.275153032
## [31] -1.789340704 -1.273459981 1.193927825 -1.246932674 -0.430047712
## [36] -1.408989494 -1.111447945 -1.280200478 0.087413286 0.679220848
## [41] 0.290873113 1.934698137 -0.170632058 2.294484562 0.140106914
## [46] -0.617669647 1.649999618 -0.551072804 0.486863447 0.866448514
## [51] -0.325806393 -2.081384947 0.218225732 -0.194333682 -0.785738000
## [56] 0.278250713 0.601773540 0.004002865 -1.374655893 -1.331115539
## [61] 0.190527940 -0.010879909 0.566417661 -0.582226517 0.405902013
## [66] -0.809129005 0.739565224 1.791236297 -0.077479735 -0.881394205
## [71] -0.173747353 0.131494431 -1.223069551 1.664700735 -0.864902716
## [76] -0.062460642 -0.824657046 -1.218058185 1.156489655 0.535425340
## [81] -0.163024811 -0.468903190 -1.992400872 0.807773400 0.029570256
## [86] -1.065542698 0.708443728 -1.413780392 -0.816480128 0.657745237
## [91] 0.985102777 -0.119180161 0.121026086 0.909668900 0.189469398
## [96] 0.052482555 -0.472289289 -0.693373923 -0.334215899 -1.903099951
##
## [[2]]
## [1] -0.25875450 0.45192195 -0.14129965 -0.48513950 -1.19419119 0.04852296
## [7] -0.12494971 -2.69913307 -0.56923136 0.59317969 0.48855867 -0.12521792
## [13] -1.25761789 0.20287395 -1.91532248 1.67432109 0.47237159 1.41569682
## [19] 0.08588055 -1.80072157 0.75532561 -0.31036112 -1.73097833 -2.13698056
## [25] 2.36738038 0.48633857 1.09481961 0.30449038 1.01688141 2.45517490
## [31] -0.24403885 0.54310131 0.19845858 -2.06958035 0.51416551 -0.40417991
## [37] 0.35777998 -0.32998890 0.08217311 -0.25995052 -0.87586827 0.74289078
## [43] -2.68138122 -0.94789651 0.44784397 -1.28724749 -0.15622349 0.34939757
## [49] -0.05804050 1.47831075 -0.65258270 -0.25523286 -1.25245596 0.77262514
## [55] -0.90976997 -0.69172340 -0.61608640 0.76370516 -1.08557639 -0.39821755
## [61] 0.82937843 0.35700165 0.16072076 0.95697716 -0.33806032 -0.72579950
## [67] -1.69622426 1.95572036 2.66831987 2.06496139 0.82036535 -0.07806814
## [73] -0.48786746 0.84930072 -0.95746280 0.93026931 0.38254698 1.49618576
## [79] -0.46612240 0.26273926 -0.99102667 -1.06179903 0.27586663 0.94692452
## [85] 0.72777105 -0.25293070 1.48676214 0.23186813 0.27958462 0.14862272
## [91] -1.19470741 0.09171824 1.22085175 -0.55991059 0.33846373 -1.53521819
## [97] -0.23854774 0.51644745 -0.23727325 0.58340054
##
## [[3]]
## [1] 0.2664491638 -1.3469963272 -0.8526350420 -0.4113540385 -0.6698965617
## [6] -0.1069834877 -0.9277972315 0.4348533514 -0.0158461161 -0.6496568470
## [11] 1.3404006827 0.3308553677 -0.0008524137 1.0932070221 1.1595245506
## [16] 0.0970402348 -0.3954985959 -0.4148154462 -0.9173273893 -0.5441391984
## [21] 0.1176161927 1.7239915983 -0.0479376631 0.5410962859 1.9136056395
## [26] -0.2403162233 1.5678772409 0.4771039676 0.0388510442 0.4360775197
## [31] -1.8843109374 -1.7278160519 1.8794222142 -0.0350334621 0.9952978517
## [36] 0.2965731726 -0.0089397169 -0.2440504016 -1.7747293817 -0.1599453739
## [41] 1.9116204426 1.1063735070 -1.9894549474 0.8106197600 1.0945052782
## [46] -1.4444401450 1.2114915468 -0.7866311249 -2.0708321586 0.3306083127
## [51] 0.2571921978 -0.4380882424 -1.8767536475 -0.8067906332 0.3285759849
## [56] 0.0083665339 0.8463602573 -1.5346139219 -0.0353043768 1.4238938000
## [61] -0.9307764997 1.0018625824 -0.0897035610 0.9342787542 -0.5220418242
## [66] -0.9382625616 1.2278393538 -0.2433379966 0.2694431409 1.4270790033
## [71] -1.1447635626 0.8922605510 0.0790918016 0.3463267640 -1.2620371186
## [76] 0.8359400483 -1.2621666167 0.1493675938 -0.4874471285 2.2071080499
## [81] 0.0770783378 0.7123603570 1.0507096270 0.2724235769 -0.4240092719
## [86] 2.5187562528 -0.0017295860 -1.5659889251 -1.9915300574 -1.4957999457
## [91] 0.2514953082 -0.8182432673 0.8301238234 -1.1562445178 -0.1441958015
## [96] 1.1723315781 0.1831991812 -0.6985203200 -0.4631891217 -0.4787516183
##
## [[4]]
## [1] 1.31014158 1.09819466 1.64324210 0.39593137 0.61463274 -0.43683054
## [7] -0.56982943 0.78423560 0.29079922 -1.28144712 -0.95320981 0.47832305
## [13] -0.89843251 0.06142016 0.09834140 -0.93750994 -0.22114701 -0.50447853
## [19] 1.62135004 0.40054994 0.50377989 0.85258426 0.01601205 -0.98150469
## [25] 0.01879710 0.56958632 0.10405552 0.72039850 -0.54796577 0.55132606
## [31] -0.07849753 -0.70235630 -1.70546632 -0.67537030 -1.88424294 1.10131999
## [37] -0.93803709 0.30884776 0.38639004 0.26406936 -1.48220109 0.64941069
## [43] -1.26245228 -1.01196361 0.26655677 1.61573387 -0.24499703 -1.86615753
## [49] -0.74331502 -1.66625739 1.19375590 -1.29834857 1.03931548 0.09209179
## [55] 0.36417167 1.25497932 1.27163836 -1.08423536 0.32463046 1.23838613
## [61] 0.61505477 -1.39306979 -1.01347083 -0.65377057 -0.67234873 -0.15951329
## [67] -1.09475421 -1.24828431 0.44936851 -0.81031734 0.48577901 -0.44783374
## [73] 0.13878656 -0.42861642 1.05753379 0.80005894 -0.56816795 1.42707901
## [79] -0.24334500 -0.42674961 0.83810754 0.25860309 0.76271285 -0.83189895
## [85] -1.83769866 0.13777046 -0.34121388 1.28152635 0.02692627 0.65523055
## [91] -0.34789338 -1.27102060 0.10899483 1.00604579 -0.82845156 0.66493483
## [97] 0.41550756 1.49611518 2.54392757 -0.08039012
##
## [[5]]
## [1] -0.97244116 -0.05975831 0.24720098 -0.74673643 0.67336181 -1.84504878
## [7] -0.10088763 0.54085362 0.19802171 -0.21846188 -1.35504038 -1.00568442
## [13] -1.66143029 0.32770743 -0.87494585 1.42240563 1.33871389 -0.49724504
## [19] 0.23183020 -1.28236562 0.94682403 0.15097940 -0.08996773 -1.87922549
## [25] 0.56434072 1.01141751 0.59054641 0.90708246 1.81054234 1.52125463
## [31] 1.59879629 0.65703478 -1.36100263 1.52636999 -0.67568978 1.18846185
## [37] -0.71371197 -0.62705645 -0.34696123 1.81946720 -0.14410534 0.77391802
## [43] -1.40734286 -0.22652747 -0.08663243 0.24917797 0.10482833 0.40064474
## [49] -0.11465530 1.67669566 0.89489601 -1.18726409 -0.69802085 -0.34089280
## [55] -0.31607492 -1.19132141 -1.34752712 0.06417591 0.57868314 1.93393514
## [61] 1.29099212 0.28454888 -1.05159708 -0.12011029 -1.39846790 -0.34956404
## [67] 1.15216589 0.47442520 0.42866114 1.24934339 -0.17264100 -0.18756486
## [73] 1.52868692 -0.50630793 -0.52108509 -2.27123722 0.10655986 -1.07339635
## [79] -0.53370249 1.60949570 -0.08346146 -1.11549234 -1.60046934 -0.70496768
## [85] 2.72371679 -0.15590380 -1.05128938 0.86727635 0.28486870 -1.34945579
## [91] -0.81570377 -1.37540652 0.69447464 -0.31187353 -2.04954616 0.56538309
## [97] 0.55236386 1.42950364 1.15527183 -0.17463612In questo caso, è chiaro che x è un placeholder che assume il valore di ogni elemento della lista list_vec.
L’uso di funzioni anonime è estremamente utile e chiaro una volta compresa la notazione. Tuttavia per funzioni più complesse è più conveniente scrivere salvare la funzione in un oggetto e poi applicarla come per mean. Usando sempre l’esempio di centrare la variabile possiamo:
Possiamo comunque applicare funzioni complesse come anonime semplicemente utilizzando le parentesi graffe proprio come se dovessimo dichiarare una funzione:
center_vec <- function(x){
return(x - mean(x))
}
centered_list <- lapply(list_vec, function(x){
res <- x - mean(x)
return(res)
})Un ultimo aspetto riguarda un parallismo tra x nei nostri esempi e inei cicli for che abbiamo visto in precedenza. Proprio come i, x è una semplice convenzione e si può utilizzare qualsiasi nome per definire l’argomento generico. Inoltre, è utile pensare a x proprio con lo stesso ruolo di i, infatti se pensiamo alla funzione in precedenza, x ad ogni iterazione prende il valore di un elemento di list_vec proprio come utilizzare il ciclo for non con gli indici ma con i valori del vettore su cui stiamo iterando. Qualche volta infatti può essere utile applicare un principio di indicizzazione anche con l’ *apply family:
means <- lapply(seq_along(list_vec), function(i) mean(list_vec[[i]]))
means
## [[1]]
## [1] -0.1744844
##
## [[2]]
## [1] -0.001581971
##
## [[3]]
## [1] 0.003746107
##
## [[4]]
## [1] -0.1040844
##
## [[5]]
## [1] 0.2978849In questo caso l’argomento non è più la lista ma un vettore di numeri da 1 alla lunghezza della lista (proprio come nel ciclo for). La funzione anonima poi prende come argomento i (che ricordiamo può essere qualsiasi nome) e utilizza i per indicizzare e applicare una funzione. In questo caso non è estremamente utile, ma con questa scrittura abbiamo riprodotto esattamente la logica del ciclo for in un modo estremamente compatto.
14.3.2 apply
La funzione apply viene utilizzata su matrici, dataframe per applicare una funzione ad ogni dimensione (riga o colonna). La struttura della funzione è questa:
Dove:
Xè il dataframe o la matriceMARGINè la dimensione su cui applicare la funzione:1= riga e2= colonnaFUNè la funzione da applicare
14.3.3 tapply
tapply è utile quando vogliamo applicare una funzione ad un elemento che viene diviso in base ad un’altra variabile. La scrittura è la seguente:
Dove:
Xè la variabile principaleINDEXè la variabile in base a cui suddividereXFUNè la funzione da applicare
Esempi
my_data <- data.frame(
y = sample(c(2,4,6,8,10), size = 32, replace = TRUE),
gender = factor(rep(c("F", "M"), each = 16)),
class = factor(rep(c("3", "5"), times = 16))
)
head(my_data, n = 4)
## y gender class
## 1 8 F 3
## 2 10 F 5
## 3 2 F 3
## 4 4 F 5
# Media y per classe
tapply(my_data$y, INDEX = my_data$class, FUN = mean)
## 3 5
## 5.875 6.625
# Media y per classe e genere
tapply(my_data$y, INDEX = list(my_data$class, my_data$gender), FUN = mean)
## F M
## 3 6.50 5.25
## 5 5.75 7.5014.3.4 lapply
E’ forse la funzione più utilizzata e generica. Viene applicata ad ogni tipo di dato che sia una lista di elementi o un vettore. La particolarità è quella di restituire sempre una lista come risultato, indipendentemente dal tipo di input. La scrittura è la seguente:
Dove:
Xè il vettore o listaFUNè la funzione da applicare
Esempi
my_list <- list(
sample_norm = rnorm(10, mean = 0, sd = 1),
sample_unif = runif(15, min = 0, max = 1),
sample_pois = rpois(20, lambda = 5)
)
str(my_list)
## List of 3
## $ sample_norm: num [1:10] 0.343 1.371 0.26 0.482 0.309 ...
## $ sample_unif: num [1:15] 0.031 0.011 0.882 0.113 0.323 ...
## $ sample_pois: int [1:20] 2 3 7 9 5 3 3 5 2 4 ...
# Media
lapply(my_list, FUN = mean)
## $sample_norm
## [1] 0.5029392
##
## $sample_unif
## [1] 0.3935366
##
## $sample_pois
## [1] 4.2514.3.5 sapply
sapply ha la stessa funzionalità di lapply ma ha anche la capacità di restituire una versione semplificata (se possibile) dell’output.
Esempi
# Media
sapply(my_list, FUN = mean)
## sample_norm sample_unif sample_pois
## 0.5029392 0.3935366 4.2500000Per capire la differenza, applichiamo sia lapply che sapply con gli esempi precedenti:
sapply(list_vec, mean)
## [1] -0.174484405 -0.001581971 0.003746107 -0.104084425 0.297884925
lapply(list_vec, mean)
## [[1]]
## [1] -0.1744844
##
## [[2]]
## [1] -0.001581971
##
## [[3]]
## [1] 0.003746107
##
## [[4]]
## [1] -0.1040844
##
## [[5]]
## [1] 0.2978849
sapply(list_vec, mean, simplify = FALSE)
## [[1]]
## [1] -0.1744844
##
## [[2]]
## [1] -0.001581971
##
## [[3]]
## [1] 0.003746107
##
## [[4]]
## [1] -0.1040844
##
## [[5]]
## [1] 0.2978849Come vedete, il risultato di queste operazioni corrisponde ad un valore per ogni elemento della lista list_vec. lapply restituisce una lista con i risultati mentre sapply resituisce un vettore. Nel caso di risultati singoli come in questa situazione, l’utilizzo di sapply è conveniente mentre mantenere la struttura a lista può essere meglio in altre condizioni. Possiamo comunque evitare che sapply semplifichi l’output usando l’argomento simplify = FALSE.
14.3.6 vapply
Esempi
vapply è una ancora una volta simile sia a lapply che a sapply. Tuttavia richiede che il tipo di output sia specificato in anticipo. Per questo motivo è ritenuta una versione più solida delle precedenti perchè permette più controllo su quello che accade.
# Media
vapply(my_list, FUN = mean, FUN.VALUE = numeric(length = 1L))
## sample_norm sample_unif sample_pois
## 0.5029392 0.3935366 4.2500000In questo caso come in precendeza definiamo la lista su cui applicare la funzione. Tuttavia l’argomento FUN.VALUE = numeric(length = 1L) specifica che ogni risultato dovrà essere un valore di tipo numeric di lunghezza 1. Infatti applicando la media otteniamo un singolo valore per iterazione e questo valore è necessariamente numerico.
sapply() non restituisce sempre la stessa tipologia di oggetto mentre vapply() richiede sia specificato il tipo di l’output di ogni iterazione.
x1 <- list(
sample_unif = c(-1, runif(15, min = 0, max = 1)),
sample_norm = rnorm(5, mean = 0, sd = 1),
sample_pois = rpois(20, lambda = 5)
)
x2 <- list(
sample_gamma = c(-1, rgamma(10, shape = 1)),
sample_unif = c(-2, runif(15, min = 0, max = 1)),
sample_pois = c(-3, rpois(20, lambda = 5))
)
negative_values <- function(x) x[x < 0]
sapply(x1, negative_values)
## $sample_unif
## [1] -1
##
## $sample_norm
## [1] -0.95907200 -0.08395547
##
## $sample_pois
## integer(0)
sapply(x2, negative_values)
## sample_gamma sample_unif sample_pois
## -1 -2 -3
vapply(x1, negative_values, FUN.VALUE = numeric(1))
## Error in vapply(x1, negative_values, FUN.VALUE = numeric(1)): values must be length 1,
## but FUN(X[[2]]) result is length 2
vapply(x2, negative_values, FUN.VALUE = numeric(1))
## sample_gamma sample_unif sample_pois
## -1 -2 -314.3.7 Lista di funzioni a lista di oggetti
L’*apply family permette anche di estendere la formula “applica una funzione ad una lista di argomenti” applicando diverse funzioni inm modo estremamente compatto. Le funzioni infatti sono oggetti come altri in R e possono essere contenute in liste:
list_funs <- list(
"mean" = mean,
"median" = median,
"sd" = sd
)
lapply(list_funs, function(f) sapply(list_vec, function(x) f(x)))
## $mean
## [1] -0.174484405 -0.001581971 0.003746107 -0.104084425 0.297884925
##
## $median
## [1] -0.133687067 0.082444857 0.002455108 -0.008867830 0.209584846
##
## $sd
## [1] 1.0286259 1.0565268 1.0279756 0.9351077 1.0405497Quello che abbiamo fatto è creare una lista di funzioni e poi scrivere due lapply e sapply in modo nested. Proprio come quando scriviamo due loop nested, la stessa funzione viene applicata a tutti gli elementi, per poi passare alla funzione successiva. Il risultato infatti è una lista dove ogni elemento contiene i risultati applicando ogni funzione. Questo tipo di scrittura è più rara da trovare, tuttavia è utile per capire la logica e la potenza di questo approccio.
:::
14.3.8 mapply
mapply è la versione più complessa di quelle considerate perchè estende a n il numero di liste che vogliamo utilizzare. La scrittura è la seguente:
Dove:
FUNè la funzione da applicare...sono le liste di elementi su cui applicare la funzione. E’ importante che tutti gli elementi siano della stessa lunghezza
Proviamo a generare dei vettori da una distribuzione normale, usando la funzione rnorm() con diversi valori di numerosità, media e deviazione standard.
ns <- c(10, 3, 5)
means <- c(10, 20, 30)
sds <- c(2, 5, 7)
mapply(function(x, y, z) rnorm(x, y, z), # funzione
ns, means, sds) # argomenti
## [[1]]
## [1] 6.953099 6.854824 9.080728 11.687548 7.215676 7.706871 11.480102
## [8] 7.142393 8.784290 13.292173
##
## [[2]]
## [1] 21.99553 14.81288 18.84860
##
## [[3]]
## [1] 33.26673 22.67479 26.38153 26.86117 25.80392La scrittura è sicuramente meno chiara rispetto agli esempi precedenti ma l’idea è la seguente:
- la funzione anonima non ha solo un argomento ma n argomenti
- gli argomenti sono specificati in ordine, quindi nel nostro esempio
x = ns, y = means e z = sds - ogni iterazione, la funzione
rnormottiene come argomenti una diversa numerosità, media e deviazione standard
14.4 Replicate
replicate è una funzione leggermente diversa ma estremamente utile. Permette di ripetere una serie di operazioni un numero prefissato di volte.
Dove:
nè il numero di ripetizioniexprè il codice da ripetere
Esempi
- Semplice
sample_info <- replicate(n = 1000,{
my_sample <- rnorm(n = 20, mean = 0, sd = 1)
my_mean <- mean(my_sample)
return(my_mean)
})
str(sample_info)
## num [1:1000] 0.395 -0.057 0.252 0.225 0.286 ...- Complesso
sample_info <- replicate(n = 1000,{
my_sample <- rnorm(n = 20, mean = 0, sd = 1)
my_mean <- mean(my_sample)
my_sd <- sd(my_sample)
return(data.frame(mean = my_mean,
sd = my_sd))
}, simplify = FALSE)
sample_info <- do.call("rbind", sample_info)
str(sample_info)
## 'data.frame': 1000 obs. of 2 variables:
## $ mean: num 0.0966 -0.2776 0.1665 0.166 -0.1766 ...
## $ sd : num 1.093 1.059 1.105 1.109 0.954 ...
head(sample_info)
## mean sd
## 1 0.09660155 1.0926324
## 2 -0.27757342 1.0591981
## 3 0.16649003 1.1050091
## 4 0.16595363 1.1089836
## 5 -0.17656075 0.9537385
## 6 -0.18156384 0.9634895E’ importante sottolineare che la ripetizione è alla base di qualsiasi struttura iterativa che abbiamo visto finora. Infatti lo stesso risultato (al netto di leggibilità, velocità e versalità) lo possiamo ottenere indistintamente con un ciclo for, lapply o replicate. Riprendendo l’esempio precedente:
# Replicate
sample_info <- replicate(n = 1000,{
my_sample <- rnorm(n = 20, mean = 0, sd = 1)
my_mean <- mean(my_sample)
return(my_mean)
})
str(sample_info)
## num [1:1000] -0.109 -0.153 0.132 0.102 -0.202 ...
# *apply
sample_info <- sapply(1:1000, function(x){
my_sample <- rnorm(n = 20, mean = 0, sd = 1)
my_mean <- mean(my_sample)
})
str(sample_info)
## num [1:1000] -0.0768 -0.1913 -0.0709 0.0338 0.0372 ...
# for
sample_info <- vector(mode = "numeric", length = 1000)
for(i in 1:1000){
my_sample <- rnorm(n = 20, mean = 0, sd = 1)
sample_info[i] <- mean(my_sample)
}
str(sample_info)
## num [1:1000] -0.314 0.1203 0.1121 -0.1172 -0.0241 ...